Illumina Complete Long Read Prep, Human
Highly accurate, high-performance full workflow solution for comprehensive human WGS with long-read data from NovaSeq platforms.
Revealing the most challenging regions of the genome
Illumina Complete Long Read sequencing technology enables highly accurate long and short reads on a single instrument
Your email address is never shared with third parties.

This novel technology will bring more light to even the darkest corners of the genome. Illumina Complete Long Reads helps resolve the most challenging regions of the genome and makes long-read sequencing accessible and streamlined by enabling short and long reads from a single platform.
Illumina Complete Long Read technology powers a portfolio of novel, high-performance assays using standard next-generation sequencing (NGS) workflows and trusted Illumina sequencing by synthesis (SBS) chemistry.
These kits offer optimized library prep and analysis performance for highly accurate, reliable results.
Tagmentation is used to normalize long fragment sizes. Long fragments are “land-marked” to capture single-molecule, long-read information and amplified. Marked fragments are tagmented to standard libraries for sequencing. Marked and unmarked data are combined to generate highly accurate complete long reads.
Learn more about

Illumina Complete Long Read Prep, Human delivers unprecedented accuracy for variant calling with PrecisionFDA Truth Challenge v2 data sets,1 as measured by F1 score (%), a calculation of true positive and true negative results as a proportion of total results.

Illumina Complete Long Reads and PrecisionFDA Truth Challenge v2 data sets
In this presentation, we share use cases of Complete Long Reads and highlight research being done by collaborators around the world.
Extract DNA from blood or saliva with no specialized protocols, no shearing, and no size selection required.
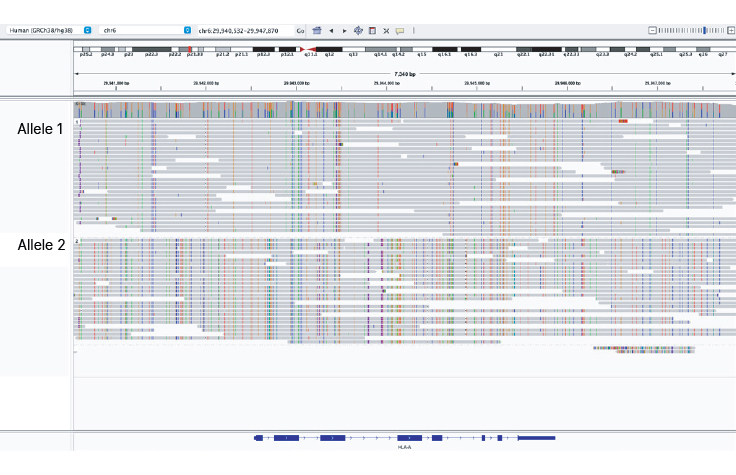
Clear haplotype assignment
Illumina Complete Long Reads can resolve highly polymorphic regions like the HLA-A gene. Uniform coverage in the HLA region enables accurate phasing of HLA alleles.
Illumina Complete Long Reads can resolve highly polymorphic regions like the HLA-A gene. Uniform coverage in the HLA region enables accurate phasing of HLA alleles.

Detection of large deletions
A heterozygous 180 bp deletion in the SEMG1 gene is clearly detected by both Illumina Complete Long Reads and on-market long reads.
A heterozygous 180 bp deletion in the SEMG1 gene is clearly detected by both Illumina Complete Long Reads and on-market long reads.
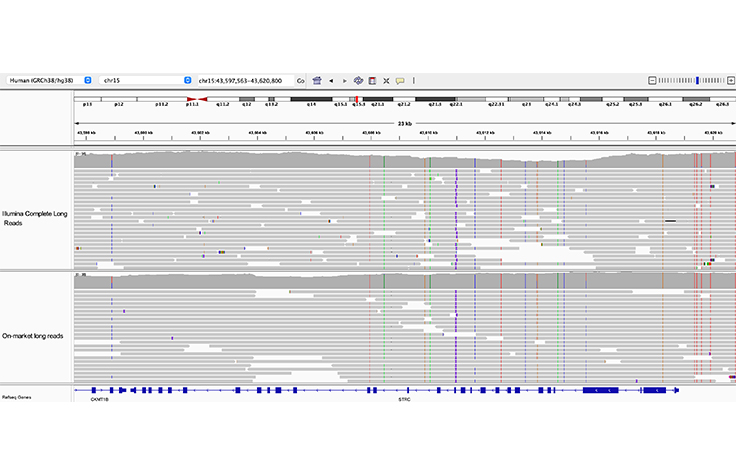
Resolution of STRC from its pseudogene
Both Illumina Complete Long Reads and on-market long reads clearly resolve the 23 kb STRC gene from its pseudogene, pSTRC.
Both Illumina Complete Long Reads and on-market long reads clearly resolve the 23 kb STRC gene from its pseudogene, pSTRC.

Enhanced coverage in challenging regions of protein-coding genes
Low-coverage regions in the RHCE gene are resolved using Illumina Complete Long Read Prep with Enrichment and the Human Comprehensive Panel.
Low-coverage regions in the RHCE gene are resolved using Illumina Complete Long Read Prep with Enrichment and the Human Comprehensive Panel.
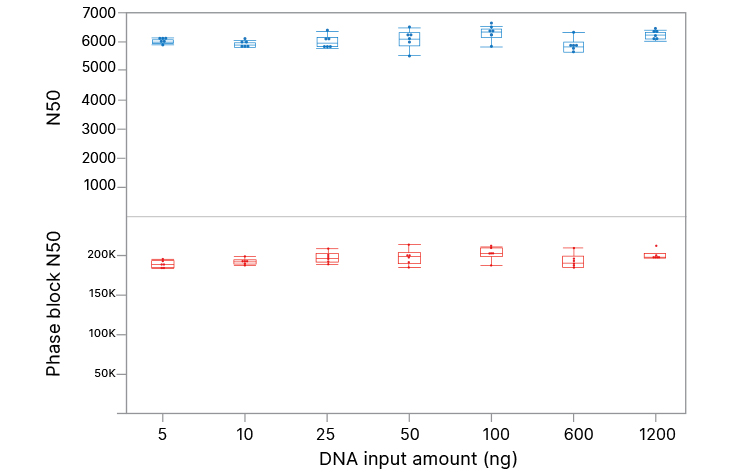
High-quality performance across a wide range of DNA inputs
Illumina Complete Long Read Prep, Human with 5 ng to 1200 ng input DNA (in triplicate) generates similar data quality for N50 and phase block N50. N50 is the sequence length of the shortest contig (or phase block) at 50% of the total assembly length.
Illumina Complete Long Read Prep, Human with 5 ng to 1200 ng input DNA (in triplicate) generates similar data quality for N50 and phase block N50. N50 is the sequence length of the shortest contig (or phase block) at 50% of the total assembly length.
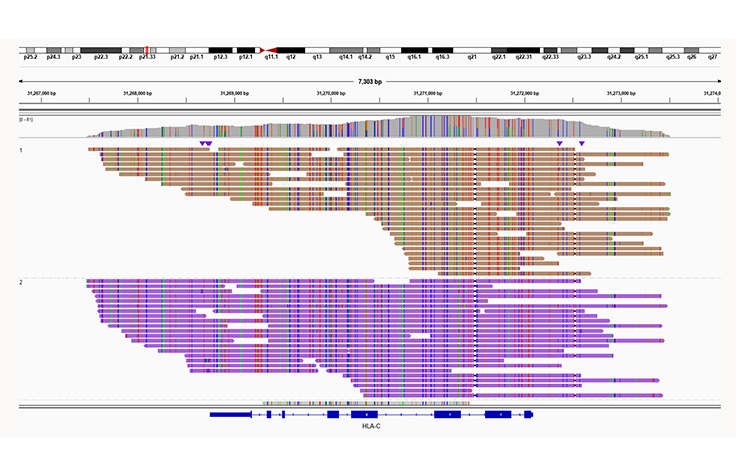
Human phasing
Perform phased sequencing with Illumina Complete Long Reads to identify co-inherited alleles, haplotype information, and phase de novo mutations.
Perform phased sequencing with Illumina Complete Long Reads to identify co-inherited alleles, haplotype information, and phase de novo mutations.

Illumina Complete Long Read technology is compatible with the NovaSeq X Plus, NovaSeq X, and NovaSeq 6000 Sequencing Systems, giving you access to both long- and short-read data on the same instrument.
Learn how your lab can benefit from the accuracy and scalability of our long-read technology.
Your email address is never shared with third parties.